
공유하기




ICML 2025 구두 발표 선정…음성 생성 성능 입증
긴 문맥 흐름 유지하며 고품질 오디오 빠르게 구현
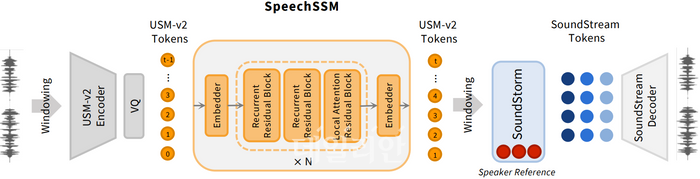 SpeechSSM 개요. ⓒ한국과학기술원
SpeechSSM 개요. ⓒ한국과학기술원
음성 기반 인공지능(AI) 기술의 한계를 넘는 장시간 음성 생성 모델이 국내 연구진에 의해 개발됐다.
한국과학기술원(KAIST)은 전기및전자공학부 노용만 교수 연구팀 박세진 박사과정생이 음성 언어 모델(SLM)의 일관성과 효율성을 높인 ‘스피치SSM(SpeechSSM)’을 개발했다고 3일 밝혔다.
스피치SSM은 텍스트로 변환하지 않고 음성을 직접 처리하면서도, 장시간 생성 시 흐름과 화자 정보를 유지할 수 있는 점이 특징이다. 이 기술은 머신러닝 최고 권위 학회인 ICML 2025에서 구두 논문 발표 대상으로 선정됐다.
기존 SLM은 음성을 세밀하게 분석해 정보를 표현하다 보니 메모리 사용량과 연산량이 급격히 증가하고, 긴 문맥에서 주제를 일관되게 유지하기 어렵다는 한계가 있었다. 연구팀은 이에 대해 어텐션(attention)과 순환(recurrent) 구조를 결합한 하이브리드 상태공간 모델을 도입해 문제를 해결했다.
이 모델은 음성 데이터를 일정한 단위로 나눠 병렬 처리하고, 다시 하나의 긴 음성 시퀀스로 연결하는 방식으로 설계돼 무한 길이의 음성도 안정적으로 생성할 수 있다. 또 음성 합성 단계에서 비자기회귀 방식(SoundStorm)을 활용해 더 빠르고 효율적으로 고품질 음성을 만들어낼 수 있다.
연구팀은 이를 평가하기 위해 직접 구축한 ‘LibriSpeech-Long’ 데이터셋을 사용했다. 기존 평가 지표인 PPL 외에도 맥락 유지력(SC-L), 시간에 따른 자연스러움(N-MOS-T) 등을 새롭게 제안해 모델 성능을 정밀하게 분석했다.
실험 결과 스피치SSM은 16분 이상의 음성 생성에서도 특정 인물이 지속적으로 등장하고, 새로운 사건과 인물들이 자연스럽게 연결되는 일관된 흐름을 보여 기존 모델과 차별화된 결과를 나타냈다.
박세진 KAIST 박사과정생은 “실제 사용 환경에서 요구되는 장시간 음성 생성에 대응할 수 있는 모델 개발을 목표로 삼았다”며 “향후 음성 콘텐츠 제작과 음성비서 등 다양한 분야에 기여할 수 있을 것”이라고 말했다.
0
0

기사 공유
댓글
-
최신순
-
찬성순
-
반대순



댓글 쓰기