×

공유하기




네이버와 공동연구…새 대형언어모델 기반 기술
기존보다 학습 속도 253%, 추론 속도 171% 향상
"대화형 추천 시스템 등 다양한 서비스 등장 기대"
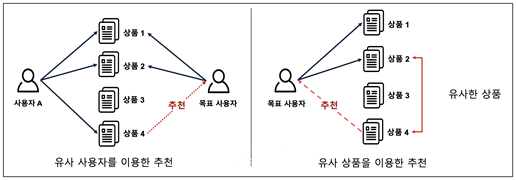 유사 사용자 이용, 유사 상품 이용한 추천 방식 그림. ⓒ한국과학기술원
유사 사용자 이용, 유사 상품 이용한 추천 방식 그림. ⓒ한국과학기술원
한국과학기술원(KAIST)은 대형언어모델 학습 없이 사용자 상품 소비 이력과 상품 텍스트 정보를 활용할 수 있는 추천시스템을 개발했다고 17일 밝혔다.
KAIST에 따르면 박찬영 산업및시스템공학과 교수 연구팀은 네이버와 공동연구를 통해 협업 필터링 기반 추천 모델이 학습한 사용자의 선호에 대한 정보를 추출하고, 이를 상품 텍스트와 함께 대형언어모델에 주입해 상품 추천의 높은 정확도를 달성할 수 있는 새로운 대형언어모델 기반 추천시스템 기술을 개발했다.
이번 연구는 기존 대비 학습 속도 253% 향상, 추론 속도 171% 향상, 상품 추천 평균 12% 성능 향상한 것으로 조사됐다.
특히 사용자 소비 이력이 제한된 퓨샷(Few-shot) 상품 추천에서 평균 20% 성능 향상, 다중 도메인 상품 추천 성능이 42% 오른 것으로 나타났다.
기존 대형언어모델을 활용한 추천 기술은 사용자가 소비한 상품 이름들을 단순히 텍스트 형태로 나열해 대형언어모델에 주입하는 방식이다. 예를 들어 ‘사용자가 영화 극한직업, 범죄도시1, 범죄도시2를 보았을 때 다음으로 시청할 영화는 무엇인가?’라고 대형언어모델에 질문하는 방식이었다.
반면 연구팀은 미리 학습된 협업 필터링 기반 추천 모델로부터 사용자 선호에 대한 정보를 추출하고 이를 대형언어모델이 이해할 수 있도록 변환하는 경량화된 신경망을 도입했다.
연구팀이 개발한 기술은 대형언어모델 추가적인 학습이 필요하지 않다는 특징을 지니고 있다.
기존 연구들은 상품 추천을 목적으로 학습되지 않은 대형언어모델이 상품 추천이 가능하게 하도록 대형언어모델을 파인튜닝하는 방법을 사용했다.
하지만 이는 학습과 추론에 드는 시간을 급격히 증가시키므로 실제 서비스에서 대형언어모델을 추천에 활용하는 것에 큰 걸림돌이 된다.
연구팀은 대형언어모델의 직접적인 학습 대신 경량화된 신경망의 학습을 통해 대형언어모델이 사용자의 선호를 이해할 수 있도록 했고, 이에 따라 기존 연구보다 빠른 학습 및 추론 속도를 달성했다.
박찬영 교수는 "제안한 기술은 대형언어모델을 추천 문제에 해결하려는 기존 연구들이 간과한 사용자-상품 상호작용 정보를 전통적인 협업 필터링 모델에서 추출해 대형언어모델에 전달하는 새로운 방법으로 이는 대화형 추천 시스템이나 개인화 상품 정보 생성 등 다양한 고도화된 추천 서비스를 등장시킬 수 있을 것"이라고 설명했다.
이어 "추천 도메인에 국한되지 않고 이미지, 텍스트, 사용자-상품 상호작용 정보를 모두 사용하는 진정한 멀티모달 추천 방법론으로 나아갈 수 있을 것"이라고 말했다.






